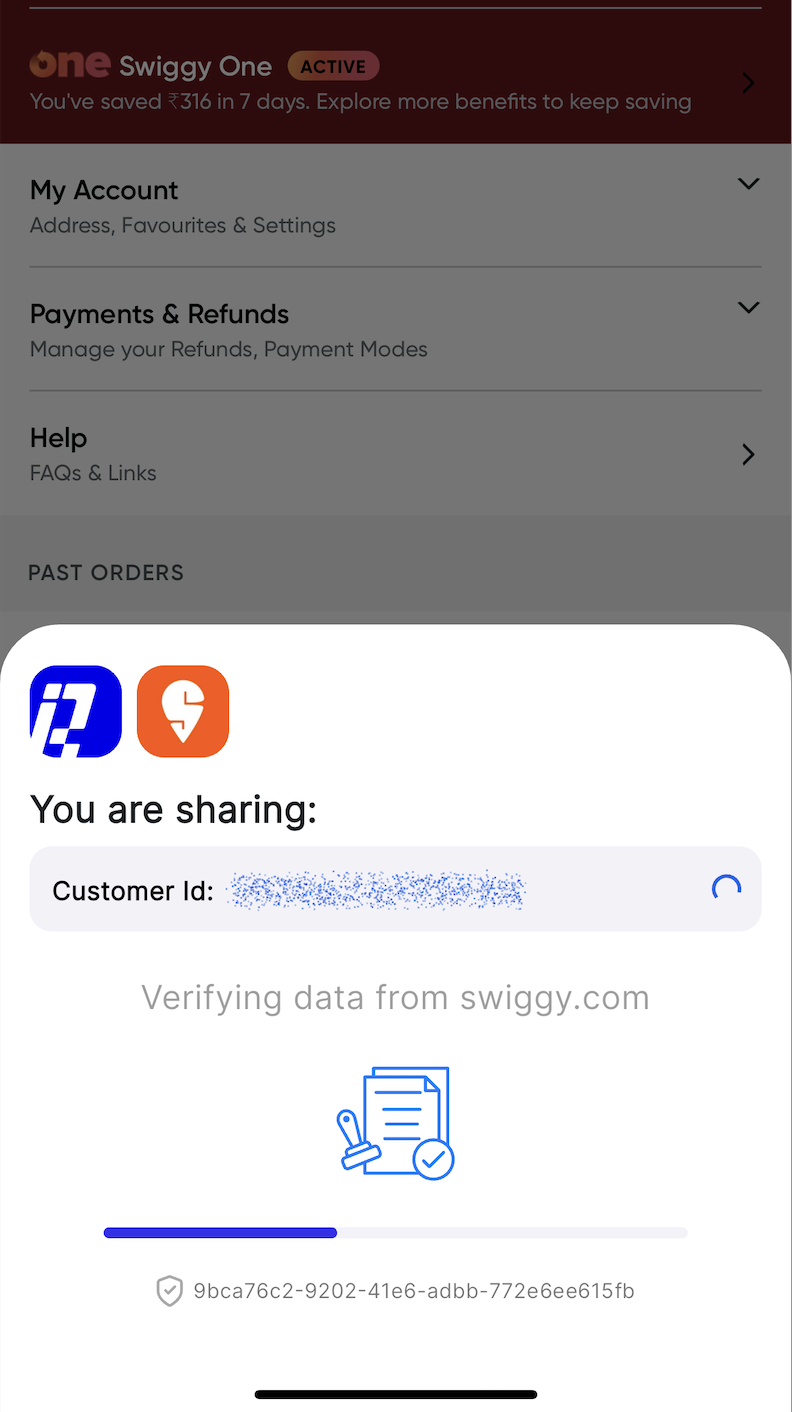
Use of OPRF to derive unique IDs

Special thanks to Aleksei Ermishkin for the idea to use OPRF and for valuable comments on this post.
Approach overview
Many use cases of Reclaim require a unique, per-user identifier. This identifier must be binding, ensuring that users cannot share it with others or create multiple identifiers. Instead of generating a public key for each user, we use a natural identifier, such as a passport number or bank account number. Since we do not aim for a globally binding ID, each application is free to choose its own natural identifier. Moreover, once the application’s lifecycle ends, the identifier can be discarded.
The challenge with this approach is that such identifiers are often sensitive and should remain hidden. Rather than using them directly, we derive a deterministic, unique identifier based on the selected natural ID.
A naive approach would be to hash the natural ID and use the hash as the identifier. However, natural IDs often have low entropy (i.e., a limited number of possible values), making them vulnerable to brute-force attacks. To mitigate this risk, Reclaim Protocol leverages Oblivious Pseudorandom Functions (OPRFs).
Understanding OPRFs and Threshold OPRFs
An OPRF is an interactive protocol between a user and a OPRF server that computes a “salted hash” of the input such that:
- The user does not learn the salt.
- The OPRF server does not learn anything about the user's input.
Formally, an OPRF allows a client to obtain the output of a pseudorandom function (PRF) on an input without revealing that input to the server. At the same time, the server, which participates in the computation, learns neither the input nor the output. This "oblivious" property enhances privacy. A limitation of this approach is that a single entity controls the salt, which we aim to avoid. To address this, we use a decentralized variant known as Threshold OPRF (T-OPRF).
A Threshold Oblivious Pseudorandom Function (T-OPRF) is a cryptographic primitive that extends the functionality of a traditional Oblivious Pseudorandom Function (OPRF) to support a threshold setting, enabling distributed and fault-tolerant computation. In a T-OPRF system, multiple servers collaborate to evaluate a PRF on a given input such that no single server learns the input or the PRF output, while a threshold subset of servers is sufficient to compute the result. In other words, instead of a single server performing the computation, a threshold number of participants collaborate to compute the function. This setup enhances security against individual server compromise. Summarizing the key features of T-OPRF:
- The user learns the PRF output corresponding to their input data but nothing else about the PRF secret
- The servers learn neither the input provided by the user nor the resulting PRF output, nor the shares of other servers
- The PRF secret is shared across n servers using a secret sharing scheme and a minimum of t out of n servers are required to participate in the protocol to compute the PRF output
- The output of the PRF is independent of any individual server’s participation, ensuring that outputs cannot be linked back to specific protocol executions and is always the same for the same input data (regardless of the chosen servers)
How the T-OPRF Protocol Works
Phases of the protocol:
- Setup:
- A secret key is generated and distributed between parties
- Each server holds a share of the secret key , denoted as , while no single entity knows entirely or any other share
- Input Commitment:
- The user generates a masked version of their input ID
- This masked input is sent to all servers
- Server Computation:
- Each server computes a partial evaluation of the PRF, using their share and the masked input
- The server outputs a share of the blinded PRF result , where represents the PRF itself
- Additionally, each server outputs the so-called DLEQ proof that their computations were honest and correct
- Aggregation and Reconstruction:
- The user collects or more shares from the servers and verifies the correctness of each of the DLEQ proofs
- Using these shares, the user combines them and unmasks the input to reconstruct the final PRF output
Deep dive into how T-OPRF works inside Reclaim
tl;dr: this is a more formal description of how Reclaim Protocol exploits T-OPRF to prove an ownership of a unique ID in a zero-knowledge manner.
Steps in Reclaim’s T-OPRF implementation:
- The client performs T-OPRF for the ID they want to hide and prove, receiving t responses and (DLEQ) proofs for each of them that the computations were carried out correctly. The client verifies the proofs, combines the responses into one, and obtains the output value.
- The client provides to the zkTLS Attestor the following data: ZKP with the ciphertext, plaintext, encryption key, the position of the ID in the plaintext, and its length. Additionally, the client supplies t proofs and responses along with the final resulting output.
- The ZKP decrypts the ciphertext, extracts the ID at the specified position and length using a precomputed bitmask, and ensures that everything matches the provided output by verifying all DLEQ proofs and other checks.
Note that, the string hashed inside the ZKP is represented as two field elements of 31 bytes each, meaning the maximum string length for OPRF is 62 bytes. For OPRF operations, we use the babyjub curve, which operates efficiently inside the SNARK and is compatible with BN254.
(Coming soon!) Handling key and OPRF servers updates
Adding new nodes while keeping the same key is not secure because the previous cohort of nodes could censor the new ones. Therefore, whenever a new node is added, the key must be regenerated. Moreover, updating the key can be reasoned by any other business or security reason. And since we aim for static per-user IDs, changing the key would result in different identifiers. This is usually not an issue, as most applications require only short-term static IDs.
Solution: Epochs
To balance security and identifier stability, we introduce epochs — fixed timeframes (e.g., a month or a year) during which a user’s ID remains unchanged.
- At the start of each new epoch, a new key is generated and distributed among an updated set of servers.
- In cases where older IDs need to persist beyond an epoch, servers retain previous key shares, allowing them to derive past identifiers upon request.
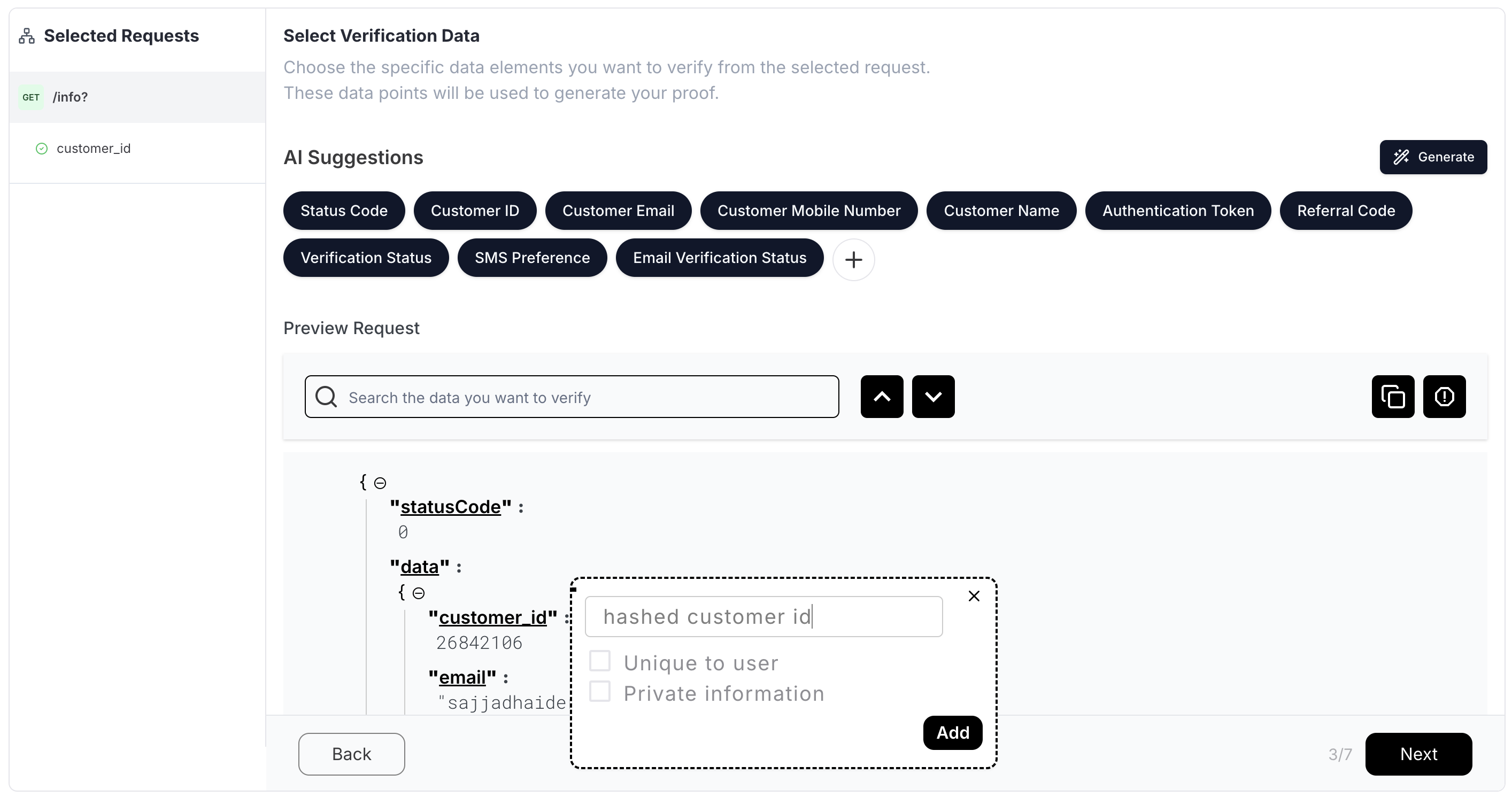
Adding OPRF mechanism to your provider using Reclaim Devtool
To use the OPRF mechanism described above in a provider, one can follow the next steps (also, see the screenshots below):
- Select Data: Click on the data you want to protect with OPRF, i.e. your ID;
- Enable OPRF: When adding a description, check the "private information" checkbox.