How does the data flow happen

Overview of Reclaim Protocol
Reclaim Protocol enables users to securely create digital proofs of their personal data (such as bank balance or employment status) directly from websites they already have legitimate access to. Users fully control what information they share, and the entire cryptographic proof generation occurs privately on their devices.
Key things to note:
- All proof generation happens on the user’s device.
- Reclaim’s attestor sees only encrypted data, not your private content.
- No Reclaim servers store user data.
- User selective disclosure of data - Complete data minimization
- Explicit Consent - Users intentionally authorize data sharing.
Data Access: Who sees what?
A core reason Reclaim’s solution is legally safe is that it clearly delineates who can access data – and it keeps almost everything in the hands of the user. Here’s a breakdown of data access and flow:
- User (Data Subject): The user logs into their account on the target website through Reclaim just as they normally would. They see and interact with their data (e.g. viewing their account page) in the secure browser environment. No data is shared with anyone unless the user approves it. In other words, the user has full knowledge and control of what data is accessed and what will be shared (this explicit user-driven action is central to the process).
- Reclaim (Attestor component): The Reclaim attestor mediates the session acting more like a transparent proxy, but it never sees sensitive personal data in plaintext. It only sees encrypted traffic and some technical details (like the fact a certain URL was fetched) – it does not learn the user’s login credentials or the actual content of the web page. The user’s password and any two-factor codes are entered in the secure session with the website and are not revealed to Reclaim. The attestor’s role is limited to certifying the process. Because Reclaim does not centrally store any user data, it is not a data controller for the content of user accounts – it’s more like a tool the user is running locally (analogous to a browser or a notary on the user’s side). Reclaim’s infrastructure simply doesn’t have a data warehouse of personal information; there’s nothing for an attacker or for Reclaim itself to mine or misuse.
- Third-Party Application (Verifier): The third-party that the user wants to share data with – say, an app/website that needs to verify the user’s employment or a decentralized service that needs to check a credential – only receives the proof or attestation that the user provides to it. This proof contains very limited information: typically just an identifier of the data source, the specific claim - a set of selective data fields (e.g. “User is a current employee of Company Y”), and cryptographic signatures. The verifier does not get the user’s entire data or login access. The proof is also read-only – it doesn’t give the verifier the ability to make transactions or changes on the original website. In privacy terms, the third-party learns only what the user wanted them to learn, nothing more. If the third-party decides to store this proof, they would then take on the responsibility of handling that minimal personal data properly (more on that under compliance). But importantly, the data is shared directly by the user to the third-party without hitting Reclaim servers, under the user’s consent; Reclaim is just enabling a secure, verifiable way to do it.
This clear allocation of data access – user sees all and decides, Reclaim sees effectively nothing sensitive, verifier sees only the attested snippet – means there is no hidden or inappropriate data flow. The user is effectively exercising their own right to access and share their personal data. From a legal perspective, this setup helps in several ways: it minimizes personal data handling by third parties, it ensures transparency (the user knows exactly what is shared), and it avoids creating new troves of personal data that could be regulated or breached.
Legal Compliance of Reclaim Protocol
Reclaim Protocol is purposefully aligned with global data protection and privacy standards.
Compliance with Website Terms of Service (ToS)
Reclaim Protocol aligns with common provisions found in most website ToS:
- Authorized Personal Use: Users log in themselves, making their own requests—aligning clearly with typical "personal use" provisions.
- No Mass Extraction: Proof creation is targeted, singular, and not continuous, thus avoiding prohibited automated extraction.
- Credential Security: Reclaim never stores user credentials or session data.
In situations where websites maintain stricter policies, users are advised to review those terms carefully and confirm compliance independently.
Reclaim Protocol vs. Web Scraping
Reclaim Protocol does not function as traditional web scraping:
- It requires explicit, user-initiated actions for data access.
- It never automates continuous or bulk data extraction.
- It does not store, aggregate, or monetize user data.
Reclaim Protocol simply provides a secure, verifiable, and user-driven approach to data portability. Its like you copying a number from your screen and sending it to someone, but safer.
Data Roles: Controller vs. Processor
- User: Serves as the data controller, deciding which information to share.
- Reclaim Protocol: Acts strictly as an infrastructure provider, without handling personal data directly.
- Third-party Applications: Become responsible as data controllers or processors upon receipt of the data.
Addressing Liability Concerns
Reclaim Protocol is structured to clearly distinguish its role as a neutral technological enabler:
- It does not encourage or participate in ToS violations.
- It emphasizes user autonomy and explicit consent.
- Its architecture inherently limits liability exposure by avoiding data aggregation or unauthorized access.
Class Action Litigation Considerations
Reclaim Protocol's design inherently reduces class-action risks:
- No aggregation or misuse of user data.
- Explicit and clear user consent mechanisms.
- Transparent documentation advising lawful usage.
Historical class action suits target large-scale misuse or mishandling of user data—risks which Reclaim Protocol explicitly mitigates.
Summary
Reclaim Protocol is a responsible, compliant, and secure solution that empowers users to exercise their data rights safely and transparently. Its privacy-focused, user-centric design aligns seamlessly with global data protection principles, positioning it as a trusted partner for enterprise clients seeking secure and compliant data verification solutions.
Appendix
How Reclaim Protocol Works
Reclaim Protocol allows a user to prove a fact about their data on a website without involving that website’s API or support.
Reclaim achieves this, by
- Mathematically proving where your data actually came from
- Only sharing the parts of your data that you want to
At first glance, this might sound like some kind of automated web scraping, but it’s not– the user is directly involved and the process uses cryptography rather than unauthorized data harvesting.
How it works: Reclaim is essentially a lightweight browser environment (available via an SDK) that the user interacts with to log into the target website. When the user initiates a proof creation, they log in to the desired site through Reclaim’s embedded browser interface. The login request and response are routed through an attestor which monitors the encrypted traffic between the user’s browser and the website. The attestor does not and cannot decrypt this traffic on its own – the data is protected by normal TLS encryption – but the user selectively shares some keys or non-sensitive parts of the request with the attestor so it can verify the request details (for example, confirming the correct URL and query was requested). The attestor can thus see the structure of the request (minus private info like passwords) and can cryptographically sign off that the right request was made to the legitimate website.
The website’s response, still encrypted, is then passed into a zero-knowledge proof circuit on the user’s device, which uses the session’s decryption key (known only to the user) as a private input to extract just the specific piece of information needed – for example, a regex match of the account balance or a status on the page. The attestor also vouches that the encrypted response fed into the ZK-proof indeed came from the website (it saw the ciphertext in transit). In the end, the user obtains a signed proof/attestation containing only the selective data they chose to prove, along with cryptographic signatures from the attestor and the proof itself, which any third-party can verify as authentic (i.e. originating from that website). Crucially, the third-party never needs to contact the original website – they can check the proof offline using the signatures and public keys, which is why we say the proof is portable and verifiable by any relying party.
High-level architecture of Reclaim Protocol
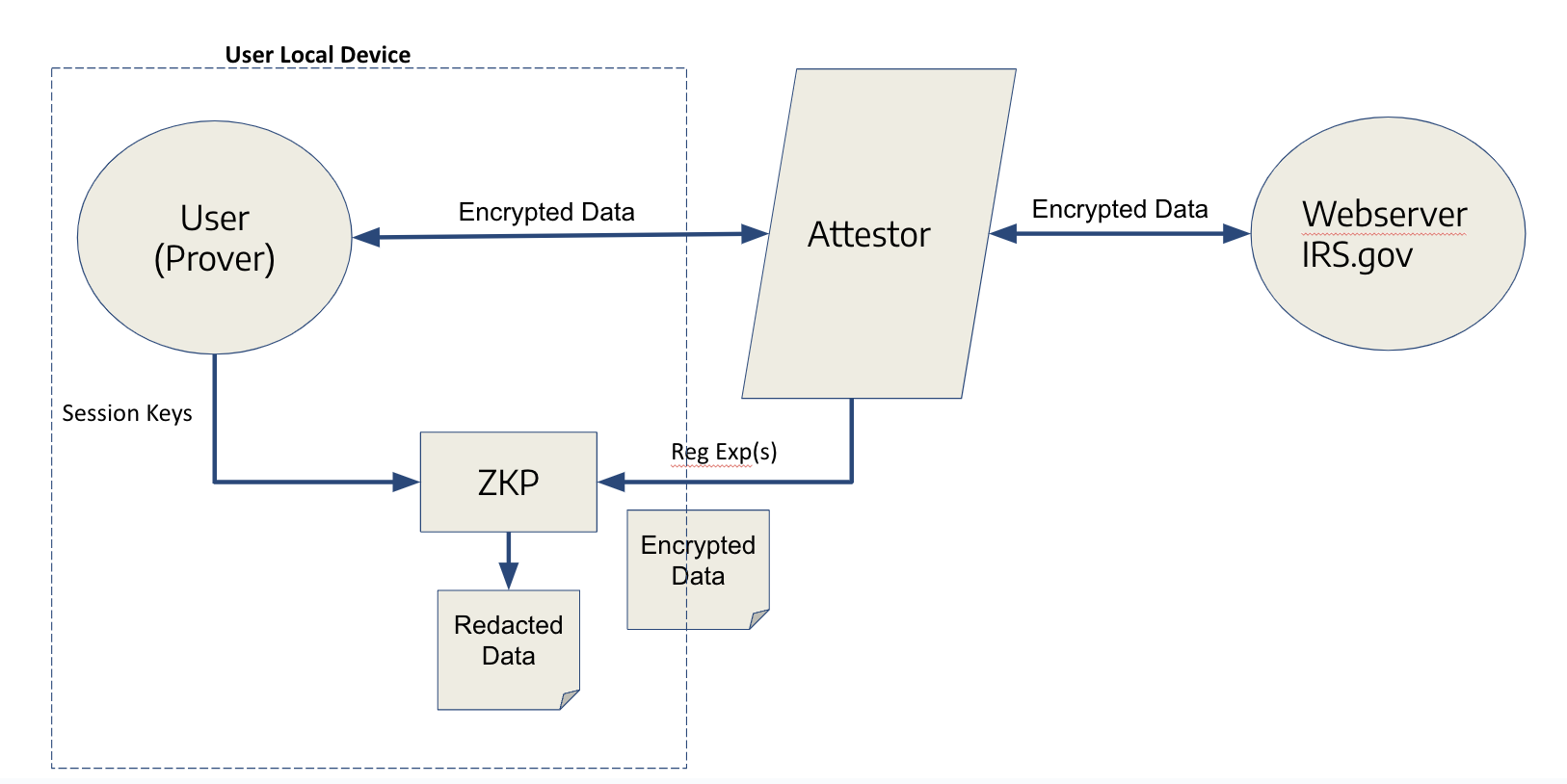
In this simplified flow, the user logs into a website through a Reclaim attestor running locally on their device, which passes the encrypted HTTPS traffic to the site. The attestor, having partial insight into the request (but not the user’s credentials), signs a statement that the correct request was made. The encrypted response is fed into a zero-knowledge circuit that extracts the required data point (e.g. a confirmation of some account detail) without revealing other information. The attestor then attests that this data came from the genuine response. The final output is a cryptographically signed proof that the user’s claim (e.g. “I have an active payroll at Company X”) is true, backed by the website data. The user can now share this proof with a third-party, who verifies the attestation’s signatures to gain confidence in the claim without ever seeing the user’s login or unrelated data.